
Loading....
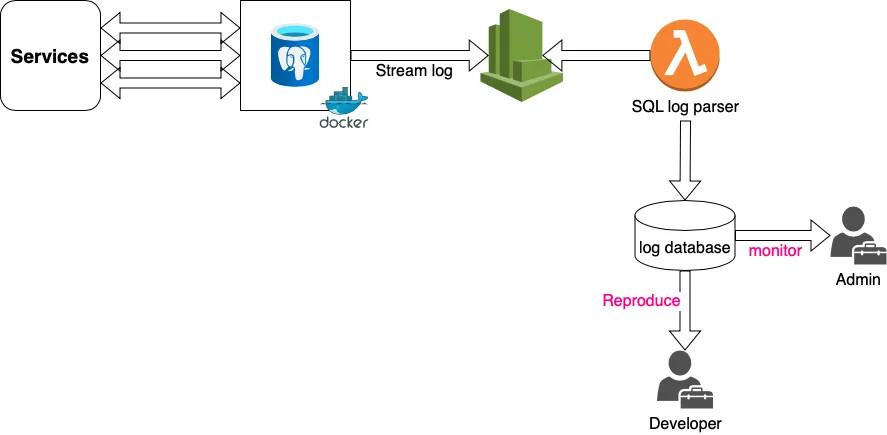
Read PostgreSQL log file, extract the SQL statements in time execution and orders. By using this method, database administrator can analyze and identify the issues, as well as back-end developer can reproduce the bugs in production environment. This method read log stream not WAL file, so there is no impact to database server. In this tutorial, the database system is containerized and AWS cloudwatch will collect it's logs
Go to IAM, create AWS role has create and upload log stream permission as follow:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Effect": "Allow",
"Resource": "*"
}
]
}
Please make sure you add restricted condition like IP, ... for security
Install AWS credential for CloudWatch in Docker environment.
[Service]
Environment=”AWS_ACCESS_KEY_ID=!aws_access_key_id
Environment=”AWS_SECRET_ACCESS_KEY=!aws_secret_access_keyExecute these commands to apply changes:
exec sudo systemctl daemon-reload # to reload daemon config
exec sudo service docker restart # restart docker
exec systemctl show — property=Environment docker # see whether the env variables existed. You can adjust log_min_duration_statement variable get SQL statements which executing duration longer than certain value, 1000ms in this case. And the rest, you should copy exactly to the bottom of postgresql.conf file.
log_destination = stderr
syslog_facility = LOCAL0
syslog_ident = 'postgres'
log_line_prefix = 'time=%t; pid=%p; %q db=%d; usr=%u; client=%h ; app=%a; line=%l ;?;'
log_temp_files = 0
log_statement = ddl
log_min_duration_statement = 1000
log_min_messages = info
log_checkpoints = on
log_lock_waits = on
log_error_verbosity = defaultIn this section, I am going to build lambda function to pull and parse Cloudwatch stream in every 15 minutes (trigger by Cloudwatch event) and and save it to AWS S3. This is sample code snippet
import boto3
import datetime
import json
import os
import pandas as pd
import io
from datetime import datetime, timedelta
import botocore.errorfactory
AWS_REGION = 'ap-northeast-1'
LOG_GROUP = os.getenv('LOG_GROUP', '!LOG_GROUP')
LOG_STREAM = os.getenv('LOG_STREAM', '!LOG_STREAM')
S3_BUCKET = os.getenv('S3_BUCKET', 'S3 Bucket')
S3_PATH = os.getenv('S3_PATH', 's3 prod')
TIME_FORMAT = '%Y-%m-%d %H:%M:%S UTC'
TODAY = datetime.now().strftime('%Y-%m-%d')
TODAY_S3_FILE = "{}/{}.csv".format(S3_PATH, TODAY)
TODAY_FILE = '/tmp/{}.csv'.format(TODAY)
client = boto3.client('logs')
s3 = boto3.client('s3')
def handler(event, context):
extract_log(client)
def getS3todf(key):
try:
obj = s3.get_object(Bucket=S3_BUCKET, Key=key)
df = pd.read_csv(io.BytesIO(obj['Body'].read()), index_col='time_utc')
return df
except Exception as ex:
return None
todayDf = getS3todf(TODAY_S3_FILE)
# get last csv
def get_begin_today():
today = datetime.utcnow().date()
return int(datetime(today.year, today.month, today.day).timestamp() * 1000)
def get_last_date():
if isDfOk(todayDf):
time = todayDf.index.max()
return int(time)
else:
return get_begin_today()
def extract_log(client):
import time
end_time=int(time.time())*1000
start_time=get_last_date()
print('start time {} ==> {} '.format(start_time, end_time))
response = client.get_log_events(
logGroupName=LOG_GROUP,
logStreamName=LOG_STREAM,
startTime=start_time,
endTime=end_time,
limit=10000
)
log_events = response['events']
data = []
for idx, each_event in enumerate(log_events):
# print(each_event)
timestamp = each_event['timestamp']
if idx + 1 < len(log_events) and log_events[idx+1]['timestamp'] == timestamp:
message = each_event['message']
message2= log_events[idx+1]['message']
splip_message=message.split(';')
if len(splip_message) > 3:
human_time=splip_message[0].split('=')[1] if len(splip_message[0].split('=')) > 1 else ''
time = int(datetime.strptime(human_time, TIME_FORMAT).timestamp()*1000)
db=splip_message[2].split('=')[1] if len(splip_message[2].split('=')) > 1 else ''
if db=='postgres':
continue
user=splip_message[3].split('=')[1] if len(splip_message[3].split('=')) > 1 else ''
client=splip_message[4].split('=')[1] if len(splip_message[4].split('=')) > 1 else ''
app=splip_message[5].split('=')[1] if len(splip_message[5].split('=')) > 1 else ''
log=splip_message[-1]
split_duration=log.split(' ms ')
if len(split_duration) > 1:
duration = split_duration[0]
duration = float(duration.split('duration: ')[-1])
sql = split_duration[1].split(': ')[-1]
split_parameter=message2.split('parameters: ')
if len(split_parameter) > 1:
parameters=split_parameter[-1].split(', ')
for param in parameters:
key = param.split('=')[0].strip()
value = param.split('=')[1].strip()
sql = sql.replace(key, value, 1)
item={'time_utc': time, 'human_time': human_time, 'db':db, 'client_ip':client, 'app': app, 'duration': duration, 'sql': sql, 'raw': message+' | '+message2}
data.append(item)
else:
item2={'time_utc': time, 'human_time':human_time, 'db':db, 'client_ip':client, 'app': app, 'duration': '', 'sql': '', 'raw': log}
data.append(item2)
df = pd.DataFrame.from_records(data, index=['time_utc'])
test = df[df.index>start_time]
if isDfOk(df):
if isDfOk(todayDf)>0:
newdf=todayDf._append(df[df.index>start_time])
newdf.to_csv(TODAY_FILE)
else:
df.to_csv(TODAY_FILE)
s3.upload_file(TODAY_FILE,S3_BUCKET, TODAY_S3_FILE)
print('DONE')
def isDfOk(df):
return df is not None and not df.empty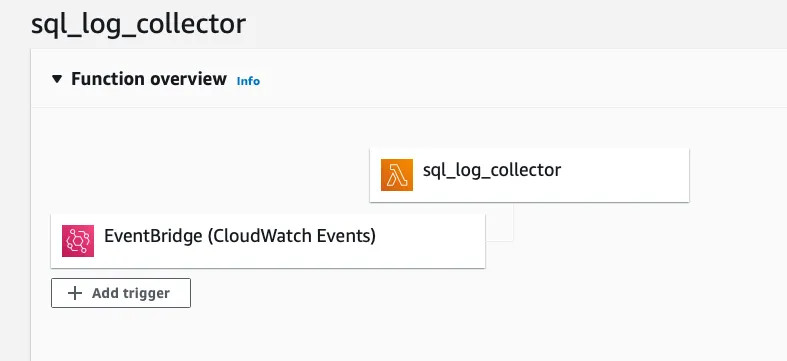
And well, That's it . If you have any questions, you can mail me. Thanks for reading!